Web scraping with golang
Written: 18 February 2018
For a personal project, I needed to scrape some stock prices. I was surprised to find out how easy it is with go. Go is incredibly productive and fast. I had earlier written the scraping code in nodejs. The go version simply destroys the nodejs version in terms of speed. In this article I will go over the code.
We need to do only two things to grab data from a web page -
- Get the content of the web page in html.
- Parse this html to get the data we need.
Getting the content of the web page
Go provides all the necessary tools to do this quite easily. The "net/http" package has everything we need. Below is the code snippet that will grab html from a webpage
Parsing the html to get the price
We will get the last traded price of Alphabet Inc. The NASDAQ symbol is GOOG. We will use google finance site to get it. We open https://finance.google.com/finance?q=NASDAQ:GOOG in a browser and we see the following:
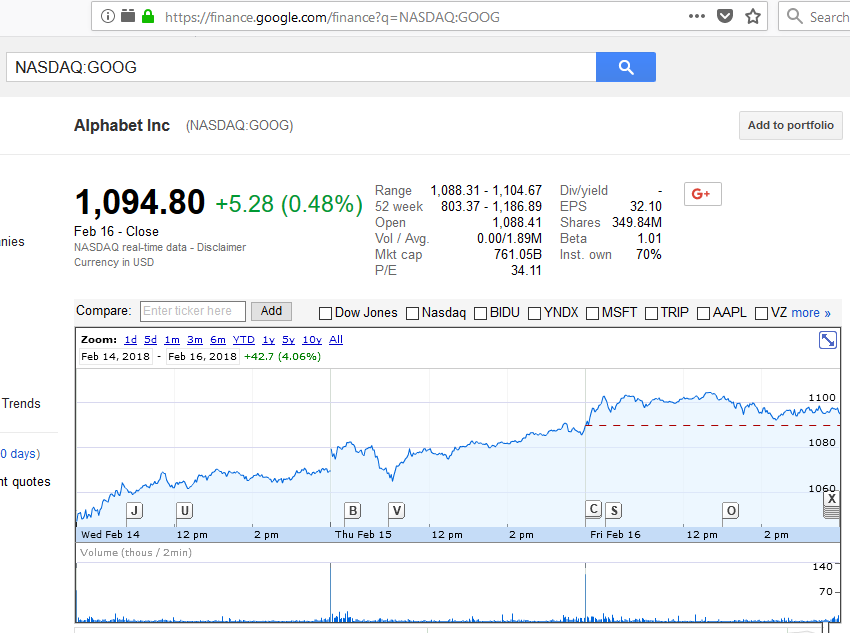
The last traded price is shown nicely. We will look at the source of this page using view source of the browser and search for the price. We find the price at several places in the html. We will use the following one -
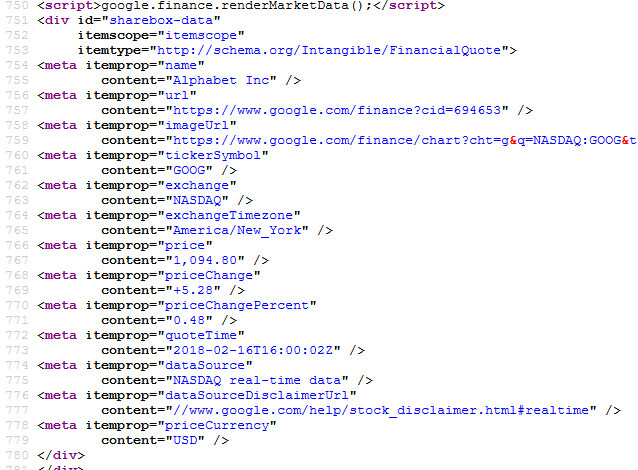
We will get price and quote time. As you can see above these are in the meta tags above. We are going to use regular expression to get them –
As you can see, its very simple to do web page scraping with go. No additional libraries are needed, go has everything you need for this.
You can view the complete working code from https://github.com/unlimit-in/scrappy